北京大学|新甫京·娱乐娱城平台网址人工智能研究院朱松纯教授、朱毅鑫助理教授及团队,与北京通用人工智能研究院张驰研究员联合在ICCV 2023会议上发表论文,题为“X-VoE: Measuring eXplanatory Violation ofExpectation in Physical Events”。
该研究的核心目标是构建能够类似人类般理解和解释物理“魔术”现象的智能体,尤其是在某些元素被遮挡或不可见的情境中。通过这项研究,团队不仅提出了一种全新的评估方法,以衡量智能体对物理常识的理解和解释能力,还展示了在无监督的条件下,如何利用物理常识推测遮挡现象背后可能的场景解释。
构建具有人类般思考能力的智能体,特别是借鉴人类婴儿早期智能的发展历程,是人工智能研究的重要方向。虽然直觉物理的重要性已逐渐得到认识(Battaglia, et al., 2013; Piloto, et al., 2022),但现有研究往往仅将其视为一个预测问题(Piloto, et al., 2022; Riochet, et al., 2021),而忽视了对观察结果的解释过程。发展心理学家通过设计“魔术”般的违反预期实验(VoE)来探索人类早期对直觉物理的认知能力(Baillargeon, et al., 1985; Baillargeon, 2004)。他们发现,人类的惊讶不是来自于物理事件本身,而是来自于在事件发生后仍然无法解释的观察结果(Andréa & Baillargeon, 2002; Baillargeon, 1994)。这揭示了在VoE实验中,解释过程是不可或缺的。论文的作者戴博强调,这项研究旨在推动AI学习和模拟人类对直觉物理的理解,特别是在视觉中对事件观测不完全时的可解释性,为后续进一步提升AI的解释能力提供了启示。
VoE通过比较婴儿对可能事件和不可能事件的反应来检验其认知能力。如图所示,即便是婴儿,也能对奇异的物理现象,例如物体神奇地穿过另一个固体或在未接触的情况下弹回,产生惊讶(surprise)反应。实验通常包括展示一系列严密设计的事件给婴儿,这些事件要么符合,要么违反婴儿对物理世界和物理规律的预期。通过这种对比实验设计,研究人员可以观察和分析婴儿是否有惊讶反应来判断婴儿对物理世界的理解。受此启发,DeepMind和MIT等机构的研究团队也采用VoE作为测试智能体对直觉物理认知的方案(Piloto, et al., 2022; Smith, et al., 2019)。然而,这些研究主要关注智能体的预测能力,而较少考虑其解释能力。因此在AI的直觉物理认知研究中,解释能力需要进一步探索。

研究团队通过如下图所示的三种不同测试方案完成对解释能力的综合评估;每个图中,上图是提供给算法的输入,下图是算法输出的对VoE的解释结果。
评估方案:这三种测试设置中最简单的是预测性设置,如下图所示。当一开始所有的物体都可被观测(即不存在隐藏变量),任何一个预测模型都可以预测视频将要发生什么,从而判断视频是否违反物理定律(即产生类似婴儿般的惊讶)。这也就意味着,在这一设置条件下,无法区分模型是否具有解释能力。然而,在假设性设置中,根据是否对隐藏因素进行推理,其结果可能会大相径庭:仅凭视觉感知,年龄越小的婴儿越可能会对球返回起点而非直接穿过感到惊讶;但随着解释能力的提高,其会认为墙后隐藏着阻挡者,因而不会感到惊讶,就像知道魔术秘密的观众不会对魔术感到惊讶一样。最后在解释性设置中,由于场景设置在最后才被揭开,这一后续提供的信息会使之前发生的物理过程违背物理定律,而仅使用预测模型无法利用这一后续信息,相反,具有解释能力的模型可以利用这一信息从而给出与预测模型完全相反的结果。通过这三种实验设置可以帮助区分智能体在处理VoE事件时是否具有解释能力。

三种不同的测试方案
数据集:基于上述三种不同的实验设置方案(分别标记为S1、S2、S3),研究者们创建了如下图所示的四个经典的测试场景,包括球体碰撞(collision)、阻挡(permanence)、物体持久性(permanance)和物体连续性(continouity)。为了测试不同的直觉物理定律,每个场景(除物体持久性)都设计了三种独特的设置:预测、假设和解释。为了准确实现VoE的效果,在每个场景中的物体前都添加了遮蔽墙,以隐藏某些物体,通过改变墙壁的升降来实现不同的效果。在每种情况下,使用具有相同设置识别码(S1、S2、S3)来连接每种设置下测试视频中的帧。从起始帧(第一行图像)到结束帧(第三行图像),黑色连接表示符合直觉物理的视频,而红色连接表示不符合直觉物理的视频。值得注意的是,该数据集的设计主要目的是用于测试模型对于直觉物理的理解,通过这种设计,可以全面评估模型在不同场景和设置下的解释能力,为进一步的研究和开发提供有价值的参考。
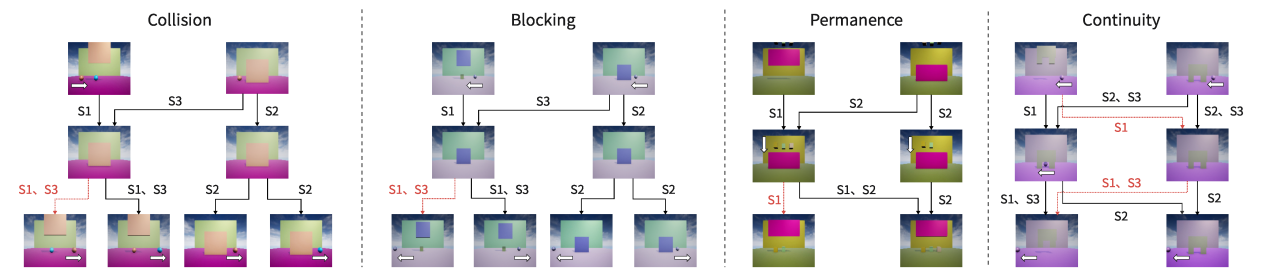
球体碰撞(collision)、阻挡(permanence)、物体持久性(permanance)和物体连续性(continouity)四个测试场景
包含可解释模块的物理学习模型:为了嵌入解释能力,研究人员在现有的基准模型PLATO的基础上增加了解释模块,构建出如图所示的解释能力集成的物理学习模型(XPL)。所提出的XPL模型包括三个主要组成部分:(1)感知模块,负责提取以物体为中心的表征,为下游处理提供基础;(2)解释模块,负责从空间和时间维度推断被遮挡物体的状态;(3)动态模块,负责学习物理知识并评估被遮挡物体的解释结果。这三个模块共同工作,使得XPL模型能够在处理物理事件时,不仅能预测结果,还能为预测结果提供合理的解释。通过这种设计,XPL模型为在AI中探讨和实现解释能力提供了新的可能路径,有助于推动相关研究的进一步发展。
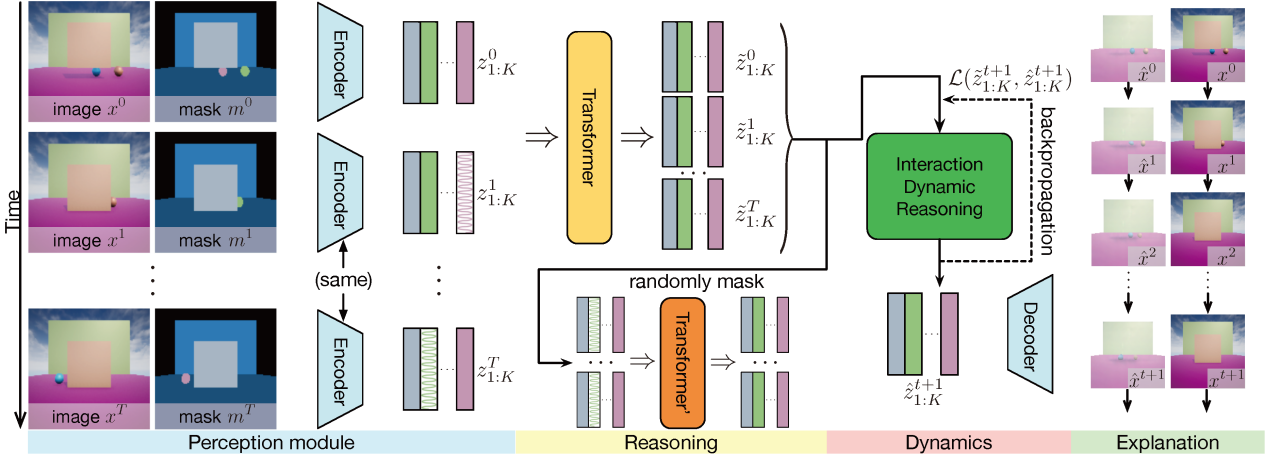
解释能力集成的物理学习模型(XPL)
可视化:该工作的一大亮点是加入了解释过程。下图可视化地展示了在阻挡场景下三种不同设置中,模型解释模块推理并恢复出的被遮挡的物理过程,从而解释了观察结果,并根据解释后的物理过程,判断是否违反了直觉物理。

在阻挡场景下三种不同设置中,模型解释模块推理并恢复出的被遮挡的物理过程
定量分析:我们从整体和对比两个角度分析了模型的准确率,并与PLATO和PhyDNet两个经典模型进行了对比。
1、综合准确率(参考Smith, et al., 2019):为了评估一个模型在违反和不违反直觉物理现象中的综合表现,综合准确率将违反和不违反的物理场景进行配对并交叉验证,测试模型的准确率。结果如下图所示:在所有测试场景中,研究者提出的XPL都表现出了更好的性能,尤其在碰撞、阻塞和持久性方面。
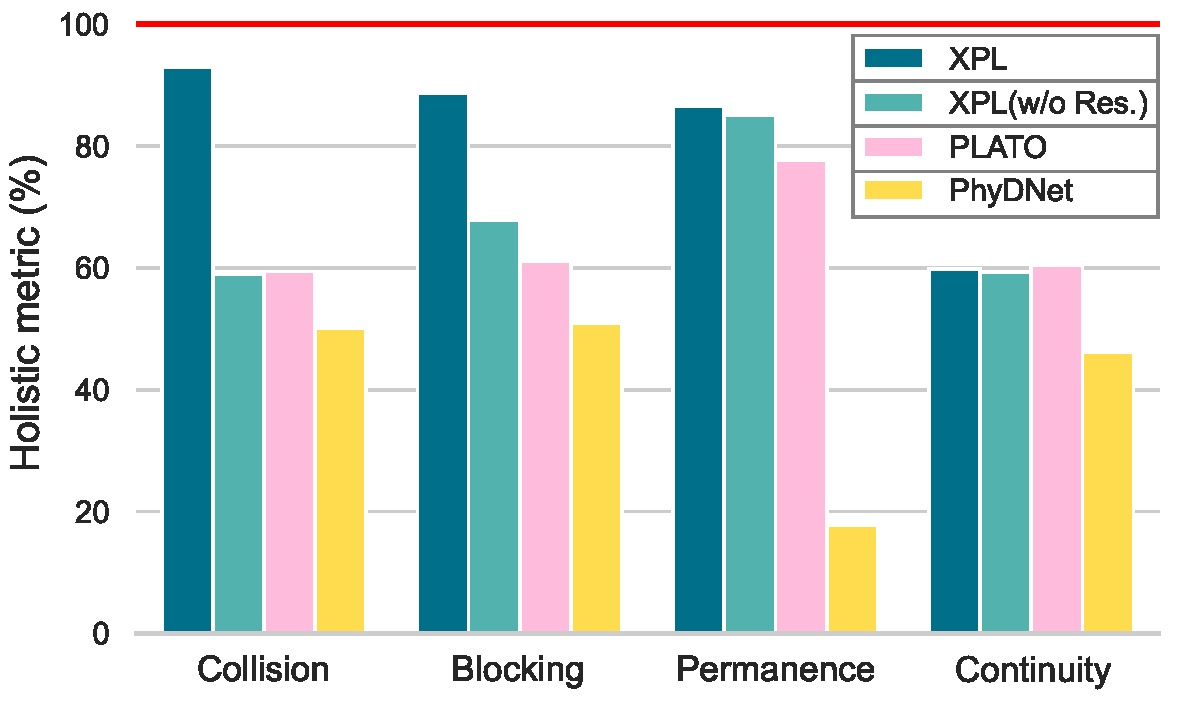
综合准确率
2、相对准确率(参考Piloto, et al., 2022):为了进一步评估模型对直觉物理的解释能力,相对准确率要求模型判断给定一组的视频中,哪一个相对更违反直觉物理。在预测环境(S1)中,因为这一任务仅依赖预测能力,所以已有的AI系统都能取得较好的结果,接近人类的水平。
真正区分出不同模型的优劣,尤其是与人类水平之间差距的,是在假设环境(S2)和解释环境(S3)中的变化率。在S2中,婴儿在实验中没有展现出VoE,这可能意味着其不具有物理常识,也有可能包含了解释能力,即相对率应为50%;转换到S3中,由于后续提供的额外信息,婴儿能分辨出VoE,即100%。这一由极少量额外信息引发的对VoE的分辨能力变化(50%到100%)是之前直觉物理模型无法实现的。而研究者提出的XPL较好地捕捉到了这一变化,尤其是在碰撞和阻塞场景中。
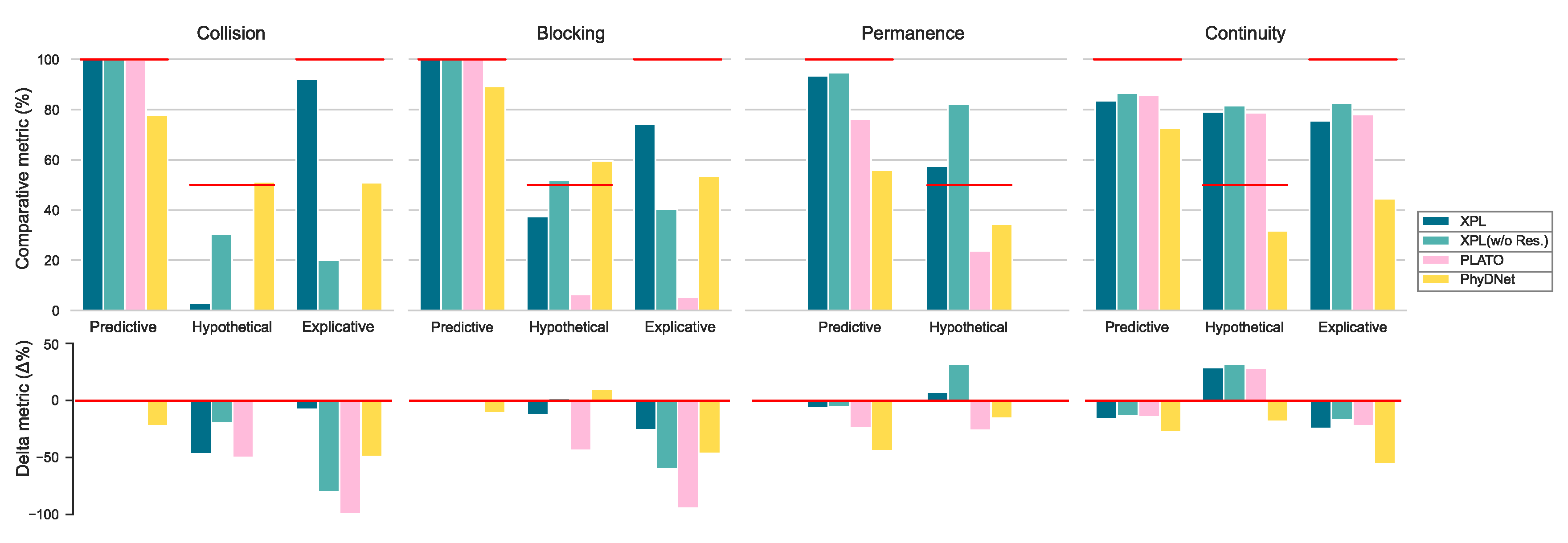
相对准确率
在这项工作中,研究人员重点突出了直觉物理理解中解释能力的重要性。具体地,研究人员提供了一个新颖的包含测试解释能力的违反预期视频数据集,同时还提出了一个包含解释能力的模型来处理相关隐藏变量(即被遮挡的物体)。
实验结果表明,该模型可以利用学到的直觉物理还原被遮挡物体,并因此在测试数据集上对比其他缺少解释过程的模型拥有更好的表现。值得注意的是,模型对被遮挡物体的解释结果经过可视化后,也能较为符合人类的认知,这突出了它对隐藏因素进行推理的能力。
本文的第一作者是北京大学|新甫京·娱乐娱城平台网址博士后戴博(朱松纯指导),通讯作者为朱毅鑫、张驰研究员。论文作者还包括清华大学|新甫京·娱乐娱城平台网址王林歌以及北京通用人工智能研究院的贾宝雄和张泽宇研究员。


